How I Ship Faster Without Breaking Things: My AI-Augmented Engineering Workflow
How I combine Claude, GitHub Copilot, and a RAG pipeline to ship features faster, reduce production incidents, and keep architectural decisions grounded in reality — and what it means for the teams I work with.
Why Most AI-Augmented Teams Still Ship Slowly
Engineering teams adopting AI tools often expect an immediate speed multiplier. What they get instead is inconsistent output, hallucinated APIs, and fragile glue code that slows the team down two weeks after deployment.
The problem isn't the tools — it's the absence of structure around them. Execution collapses when there's:
- no clear architectural ownership,
- AI output that bypasses code review or testing,
- stale documentation that means every AI session starts from scratch,
- and no feedback loop between what ships and what breaks.
The workflow below is how I solve this. I use Claude, GitHub Copilot, and a custom RAG pipeline to compress the feedback loop between design and delivery — without sacrificing architectural control or production reliability. This is what I bring to engineering teams and client projects.
The Stack (Opinionated and Boring on Purpose)

Rule: LLMs propose, CI enforces. If your pipeline doesn't fail bad AI output, your workflow is broken.
Architecture: How the Pieces Actually Work Together
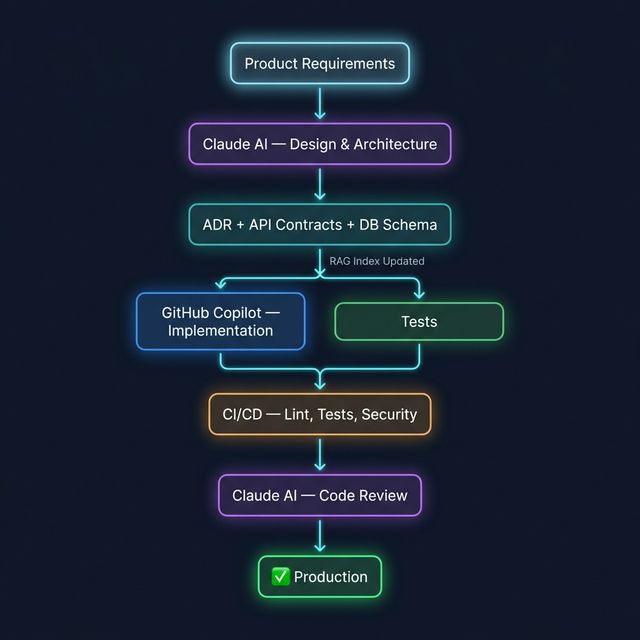
Key insight: RAG is the memory layer that keeps Claude honest. Without it, every design conversation starts from amnesia.
Claude: Your Architectural Co-Author (Not Your CTO)
I use Claude when the problem space is messy:
- Designing schemas with migration strategy
- Breaking monoliths into services
- Reviewing PRs for security and performance risks
- Threat modeling auth flows
Example prompt I actually use:
"Here's the current auth flow, schema, and traffic profile. I need to add user preferences without breaking backwards compatibility. Propose a migration plan, API changes, and rollout strategy. Constraints: zero downtime, Postgres, 50M rows."
What I expect back:
- Tradeoffs (not just one solution)
- Failure modes
- Operational risks (locks, backfills, rollbacks)
If the model can't articulate tradeoffs, I discard the design.
GitHub Copilot: Fast Hands, No Brain
Copilot shines at local context. I don't ask it to think. I ask it to type.
// Validate email, enforce length < 255, normalize casing, prevent XSS
import DOMPurify from "dompurify";
type ValidationResult = { valid: boolean; error?: string };
export function validateEmail(email: string): ValidationResult {
const sanitized = DOMPurify.sanitize(email.trim().toLowerCase());
if (sanitized.length === 0) {
return { valid: false, error: "Email is required" };
}
if (sanitized.length > 255) {
return { valid: false, error: "Email too long" };
}
const emailRegex = /^[^\s@]+@[^\s@]+\.[^\s@]+$/;
if (!emailRegex.test(sanitized)) {
return { valid: false, error: "Invalid email format" };
}
return { valid: true };
}
Rules I follow:
- Comments define intent.
- I refactor AI output aggressively.
- If Copilot introduces logic I didn't ask for, I delete it.
Copilot is speed. You are the taste filter.
Custom RAG: Stop Re-Explaining Your System to AI
Without RAG, every AI session is a first date. With RAG, it's a long-term relationship with memory.
Production-grade RAG setup:
- Index: ADRs, schema diagrams, OpenAPI specs, migration notes, incident postmortems
- Chunking by semantic sections (not arbitrary token sizes)
- Re-index on CI when docs change
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
docs = load_project_docs(["./docs", "./adrs", "./openapi.yaml"])
vectorstore = Chroma.from_documents(docs, OpenAIEmbeddings())
def ask_project_memory(question: str):
return vectorstore.similarity_search(question, k=5)
results = ask_project_memory("How does token refresh work?")
This is what makes Claude useful at scale:
- "Don't break the auth refresh token semantics."
- "This endpoint is deprecated."
- "We rejected this design in ADR-004 for a reason."
RAG is how you encode institutional memory so AI doesn't repeat past mistakes.
Workflow in Practice: Shipping a Real Feature
Example: adding "team-level feature flags" to a SaaS app.
-
Design (Claude + RAG)
- Schema changes
- API contract
- Migration strategy
- Rollout plan
-
Schema + Migrations (Claude)
- Generates migration skeletons
- I rewrite indexes and constraints manually
-
Implementation (Copilot)
- Controllers, services, tests
- Boilerplate is free; logic is mine
-
Review (Claude)
- "What breaks at 10x traffic?"
- "Where can this be abused?"
-
CI/CD Enforcement
- Migrations run on staging
- Load tests on feature flag evaluation
-
Docs + RAG Update
- ADR recorded
- RAG re-indexed
This closes the loop between design → code → memory.
Tradeoffs (No Silver Bullets)
| Pros | Cons | |------|------| | Faster iteration with fewer blind spots | You will over-trust AI early on | | Better architectural conversations | Prompting is a skill (you'll suck at first) | | Less repeated context switching | RAG infra has real maintenance cost | | Institutional knowledge doesn't rot | Junior engineers can cargo-cult AI output |
If you're not willing to review aggressively, don't use this workflow.
Mistakes I See Teams Make
- Letting AI define architecture without constraints
- Shipping AI-generated code without tests
- No CI guardrails → hallucinations reach prod
- Treating RAG as "search" instead of "system memory"
- Not recording decisions (no ADRs = no learning loop)
Practical Tips for Engineering Leads and CTOs
- Gate AI output with CI: migrations, tests, lint, security scans — if your pipeline doesn't catch bad AI output, it will reach production
- Record decisions: feed ADRs into RAG or you'll repeat the same architectural mistakes every 6 months
- Separate roles: design with Claude, write with Copilot — mixing them creates mush
- Measure outcomes: track cycle time, regression rate, and incident count before and after adopting AI tooling
- Budget for RAG infra: it's an engineering system, not a plugin — treat it that way
Why This Matters When You're Hiring or Contracting
AI doesn't replace senior engineers. It separates the ones who use it deliberately from the ones who use it carelessly.
The engineers who move fast without breaking things aren't faster because of the tools. They're faster because they've built a system around the tools:
- Architecture decisions are deliberate — not delegated to a model
- AI output is constrained by real project context — RAG, CI, and code review do the heavy lifting
- Documentation stays alive — because every new session feeds from it
- Features ship without chaos — because the workflow is repeatable, not improvised
If you're building a team or scoping a contract engagement and want an engineer who brings this kind of discipline — not just speed — I'd like to hear about what you're working on.
Want to discuss this further or work together?